AWS Lambda functions together with an Amazon Kinesis Stream offer a great way to process continuous information. I created an example project called Serverless Analytics to demonstrate this. You can use this as the starting point to create your very own Google Analytics clone and run it serverless and hopefully maintenance-free on Amazon.
Architecture
Serverless Analytics uses Amazon Kinesis to stream events to an AWS Lambda function. The JavaScript function receives up to 100 events per batch and processes the event’s payload. Based on the events, a simple request counter for your website’s URL in a DynamoDB table is increased. To easily put events to the stream, an Amazon API Gateway is used to proxy requests to Kinesis:
- Amazon Kinesis to stream visitor events
- Amazon API Gateway as HTTP proxy for Kinesis
- Amazon DynamoDB for data storage
- AWS Lambda to process visitor events
For data access, a basic dashboard is included. The dashboard is hosted on Amazon S3 and uses an API Gateway to request the data from the DynamoDB table. The basic setup looks somehow like this:
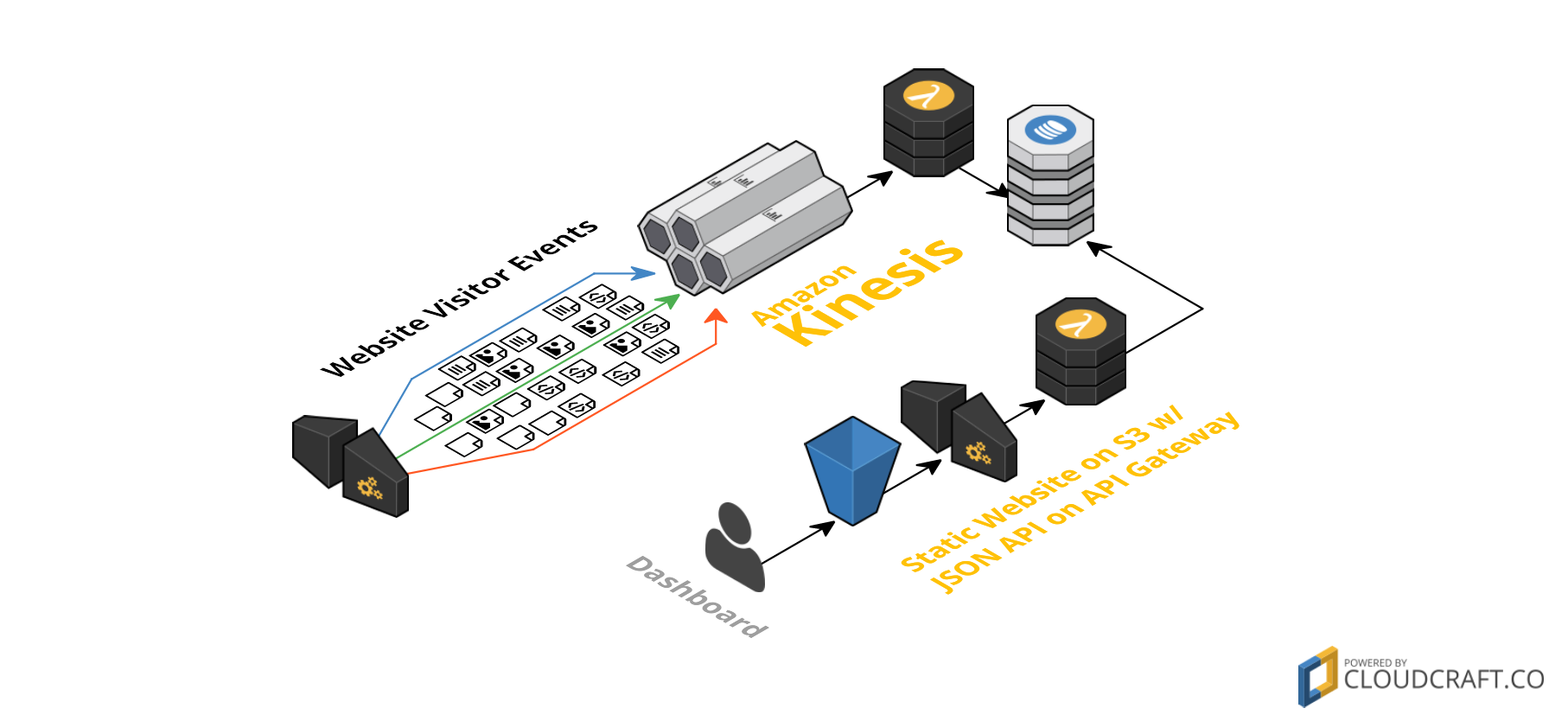
The website visitor tracking is done like any other service does it. You must add a few lines of JavaScript to your HTML pages and on every page load the browser sends a request with tracking data to a backend.
Deploying
Of course, the project relies on serverless for deployments. Just clone the repository, install all NPM/Yarn dependencies and make sure you have valid AWS credentials configured in your environment. After these simple requirements, you can run yarn deploy to get going.
After a successful deployment, the serverless-stack-output plugin writes a configuration file which is used to compile the static websites.
# Install dependencies
$ > yarn install
# Deploy
$ > yarn deploy
[…]
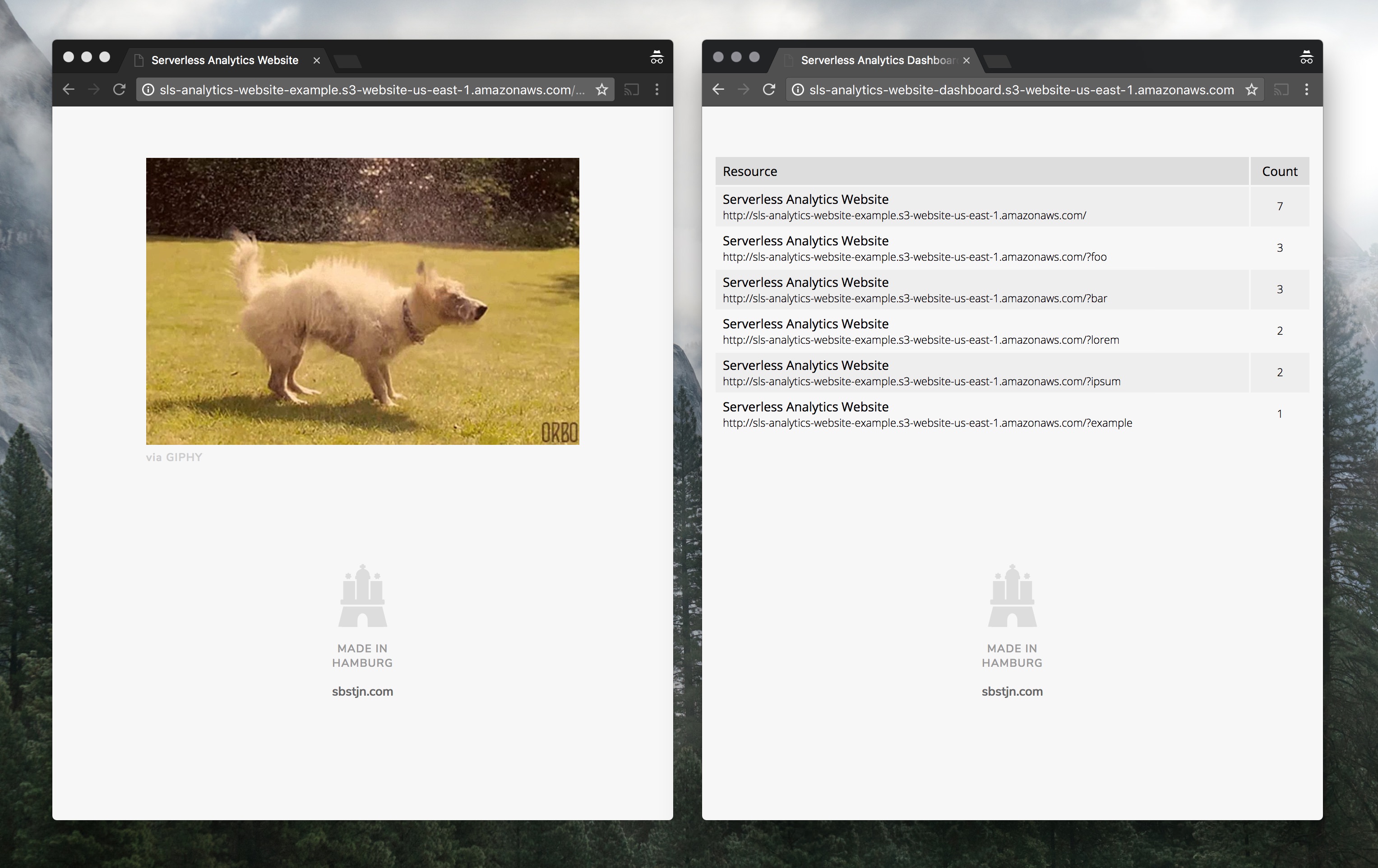
Dashboard: http://sls-analytics-dashboard.s3-website-us-east-1.amazonaws.com/
Website: http://sls-analytics-website.s3-website-us-east-1.amazonaws.com/
Just visit the website’s URL, hit a few times the refresh button in your web browser and have a look at the dashboard!
Tracking
Normally, visitor tracking works with sending an HTTP request to your tracking service (Google Analytics, e.g.). This can happen with a normal AJAX request or a non-JS fallback like a fake image.
The Serverless Analytics project uses the same approach. As said before, you have to copy a few lines of JavaScript into the footer of your website to enable tracking.
fetch("https://lqwyep8qee.execute-api.us-east-1.amazonaws.com/v1/track", {
method: "POST",
body: JSON.stringify({ url: location.href, name: document.title }),
headers: new Headers({
"Content-Type": "application/json",
}),
});
On every page load, the JavaScript above sends a request to an Amazon API Gateway with information about the current URL and the title of the website.
Processing
All events about your website visitors end up in the Kinesis Stream and are processed by the AWS Lambda function. Based on the CloudFormation resource in the serverless.yml configuration, the AWS Lambda function receives up to 100 events per invocation.
The process.js file is the place where you can add more complex metrics. If your extended event processing takes requires too much time, you can always decrease the maximum number of events that this function receives.
Storage
All data are stored in a DynamoDB. As soon as your metrics get complexer, it might be smart move to rely on a different storage solution than DynamoDB, but for the current metrics, this is a suitable solution.
The serverless-dynamodb-autoscaling plugin takes care of configuring Amazon’s native DynamoDB Auto Scaling feature, so you should be covered for traffic peaks and lots of incoming events.
Feedback
Can you image running your own Google Analytics clone with serverless? You are welcome to write some feedback on twitter 👍