The more complex your application and architecture becomes, the more complex your deployment process usually gets. Most people and engineering teams only think about pipelines as a fix path of actions, that need to happen in a specific order. That’s true, no questions about that. But your process for Continuous Integration and Continuous Delivery does not need to be a monolith!
Involved Entities
I cannot count the number of pipelines and build systems I have seen, used, fixed, and created in the past years. What most of them had in common? They are a monolith!
It does not matter if you use AWS CodePipeline, CircleCI, or Gitlab CI: All these tools expect you to configure the steps of your process and the service ensures they are triggered in the exact order. Of course, you can see a pipeline as a constant flow in one direction; the naming must have its origin somewhere. But, on the other hand, this can be just a bunch of events happening on entities involved in your process: People, Code, Changes, Versions, Artifacts, and Deployments.
All these entities have lifecycle events and unique identifiers. Why not use this to decouple the whole process of Continuous Integration and Continuous Delivery?
Semantic Version & Changelog
When working on source code, I want to focus on exactly that job. I do not want to care about integration or deployments at all. Of course, everything about automated testing and the build process, in general, is important, but that’s another context.
The most challenging job (besides tackling the actual problem) is to come up with a commit message. With Conventional Commits, you are forced to stick to a pattern of commit message styles. Together with Semantic Releases, you can analyse all commit messages and automatically generate a version in your source code repository pointing.

Regarding an event-driving approach; this scenario involves a Repository entity that receives push or commit events with an identifier of that change: the commit hash. For all these events, you can configure a handler to create a new incremented version.
Example: Semantic Releases With Github Actions
Continuous Integration
It’s not that different for continuous integration. Depending on the context, you may want to run all tasks for the integration on every push or commit event on your Repository, or you may use the previously created Version entity for running integration tasks.
When using the Version entity and a handler configured for the created event, you can run your code linting, unit tests, and integration tests for every new version. Regardless of how the source code was changed or who initialized the change. All this information may not be important for this context.
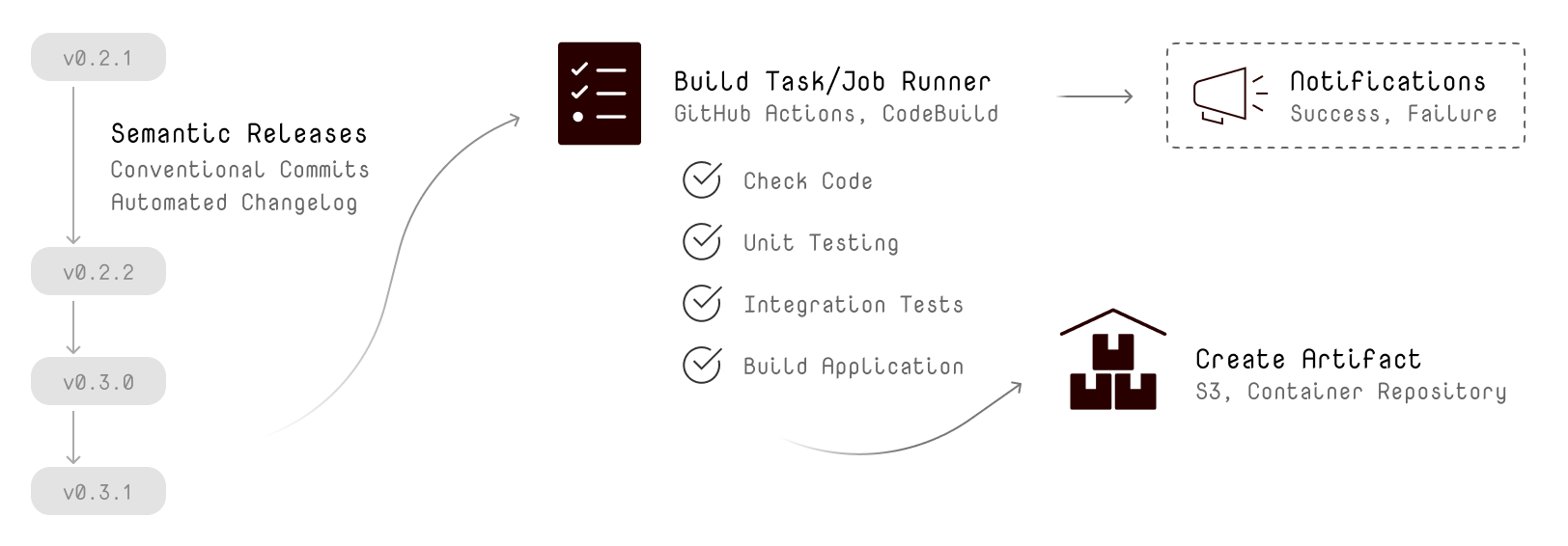
After testing and building your source code, you may want to store an artifact of that exact version somewhere; maybe in a container registry like AWS Elastic Container Registry, or just move a zip file to Amazon S3.
You do not want to watch the process of building and testing your source code. This is a continuous process, you want to expect the process to work fine and just notify you when there is something wrong. You should not waste any attention by observing the process.
Of course, your Artifact entity can trigger an event as well. Usually, you want to deploy the immutable artifacts when they have been tested and can be uniquely identified.
Example: Continuous Deployment With Github Action for AWS ECR
Continuous Deployment & Release
As you only create a new Artifact entity when all tasks for testing went fine, you can assume the integrity of your source code. Whenever there is a new artifact, a task needs to release this exact immutable artifact to your system. Regardless if you deploy it directly to production, or have a testing stage: The deployment process does not need any information about the integration tasks or source code at all.
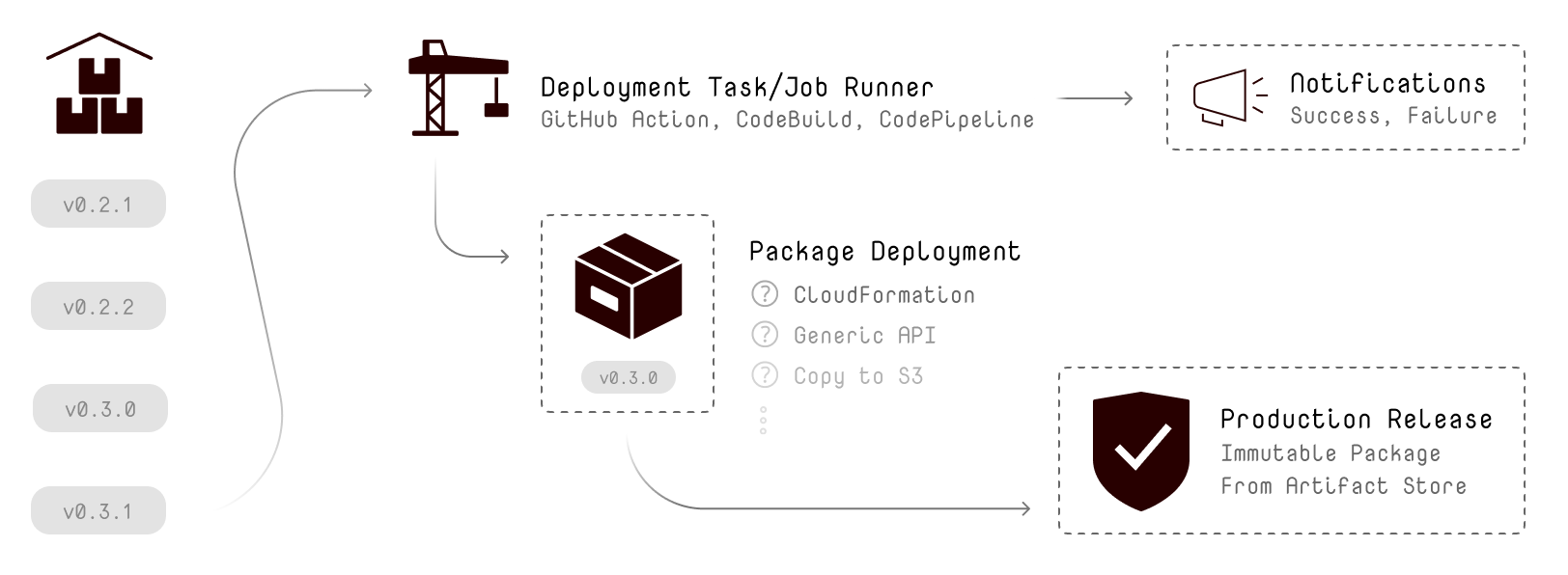
Again, You do not want to watch the process of deploying your artifact. You want to expect it is working fine and that you will get notified otherwise.
Example: Github Deployments for Continuous Releases
Example Project
I recently published an Example for AWS Lambda Container Image Support on GitHub with all these events in place for Continuous Integration and Continuous Delivery.
Do you use Event-Driven Delivery for your projects? Let me know!